НА ПУТИ К СЛЫШАЩИМ МАШИНАМ
В. ДЕМИДОВ, специальный корреспондент журнала “Наука и жизнь”.
Нам говорят: “безумец” и “фантаст”,
Но, выйдя из зависимости грустной,
С годами мозг мыслителя искусный
Мыслителя искусственно создаст!
И. Гете.
Электронные вычислительные машины, эти усилители человеческого интеллекта, с каждым годом становятся все совершеннее. Растет их быстродействие, объемистее становится память, расширяется круг решаемых задач. И при всем том, как ни стараются создатели ЭВМ, общение машины с человеком все еще затруднено: оператор держит связь с компьютером, медленно переводя свои слова на язык дырочек перфокарт и перфолент либо быстро играя на клавиатуре ввода информации под экраном дисплея. Такой разговор сродни письму, а эпистолярный жанр много проигрывает в сравнении с устной речью.
И добро бы дело заключалось только в подобного рода проигрышах! Неумение вычислительной машины воспринимать живую человеческую речь приводит к потерям куда более серьезным. Банки данных на магнитных лентах и дисках становятся все крупнее. Доступ к ним все упрощается — по крайней мере с чисто технической точки зрения. За тысячи километров может находиться такой банк от человека, решившего прибегнуть к услугам электронного отдела информации, и спрашивающий не заметит расстояния. Но для такого общения необходима весьма сложная организация дела: по телефону непосредственно к ЭВМ с вопросом не обратишься...
Почему же электронные вычислительные машины, запросто вычисляющие траекторию полета межпланетной станции и профиль крыла самолета, управляющие громадными химическими установками и прецизионными, станками, споткнулись на понимании речи?
Оказалось, лучше всех знают об этом не конструкторы ЭВМ, а физиологи. Так состоялись встречи автора с сотрудниками Лабораторий физиологии речи и биофизики речи Института физиологии имени И. П. Павлова — Людмилой Андреевной Чистович, Валерием Александровичем Кожевниковым и Эльвирой Ивановной Столяровой. Благодаря их рассказам и была написана эта статья.
ВНИЗ ПО ЛЕСТНИЦЕ, ВЕДУЩЕЙ ВВЕРХ
Машина, даже электронная, не человек. С этим тривиальным тезисом сегодня согласились самые горячие защитники мнения “ЭВМ может все”. Оказалось, может все, но только то, что способен ясно представить себе человек. А чего он не способен представить, того и компьютер не в состоянии выполнить. Люди же пока еще только в самых общих чертах знают, почему они понимают сказанное другими людьми. А такого знания недостаточно, чтобы ЭВМ могла им воспользоваться.
“Спонтанные и релаксационные переходы стремятся поддержать равновесное распределение населенностей уровней, вопреки насыщающему действию накачки. Поэтому, чтобы произошло насыщение перехода под действием накачки, вынужденные переходы должны происходить значительно чаще, чем спонтанные и релаксационные”. Все ясно? Нет? Странно... Вы ведь человек, а не ЭВМ. Ах, вы не специалист! Ну, тогда все встало на свои места.
Выходит, первое условие для того, чтобы понимать обращенную к вам речь,— определенный объем знаний. Такое требование, предъявляемое человеком к самому себе, не отменяется и в том случае, когда речь идет не о человеке, а о машине. И, что самое главное, знание—это не словарь, не энциклопедический сборник определений (хотя без (него тоже не обойтись), а модель мира, с которым сталкивается человек и с которым придется столкнуться компьютеру, коль скоро мы пожелаем поставить его на один уровень с нами. Попробуйте-ка без такой модели понять заключительные строки гоголевского “Носа”: “...А однако же, при всем том, хотя, конечно, можно допустить и то, и другое, и третье, может даже... ну да и где же не бывает несообразностей? А все, однако же, как поразмыслишь, во всем этом, право, есть что-то. Кто что ни говори, а подобные происшествия бывают на свете; редко, но бывают”.
Речь связана с высшими психическими функциями человека — мышлением и памятью. Понимание речи немыслимо без функционирования этих наиболее сложных механизмов мозга. “Язык можно рассматривать как способ передачи в память слушающего сведений о структуре памяти говорящего”,—пишут П.Линдсей и
Д.Норман в книге “Переработка информации у человека”. Чтобы научиться этому сложному искусству, маленький ребенок тратит более 20 тысяч часов. Он формирует в своем сознании понимание тысяч различных слов, имеющих смысл, то есть соотнесенных с предметами и явлениями окружающего мира и собственными действиями. Если мы хотим, чтобы ЭВМ встала на подобный уровень общения с человеком, мы обязаны обеспечить ей по крайней мере соответствующий объем зрительной и иной информации, а также возможность каким-то образом участвовать в жизни людей. Как это сделать, не знает пока никто на Земле. “...Человека отличает от машины не обладание изолированной, универсальной и нематериальной душой, а наличие у него вовлеченного в окружающий мир, самодвижущегося, материального тела”,— замечает Хьюберт Дрейфус в книге “Почему компьютеры не могут действовать?”.
Так что нам придется как бы перейти этажом ниже и посмотреть, нельзя ли резко сократить объем требований, предъявляемых к машине. Ограничимся очень узким кругом проблем и очень простым словарем, например, только информацией о прибытии и отправлении поездов. Пусть ЭВМ воспринимает человеческие слова и выдает нам нужные сведения, ориентируясь лишь на немногие ключевые слова: “прибытие”, “отправление”, “поезд номер”, числительные... Это вполне возможно. Ведь уже существуют программы, благодаря которым ЭВМ ведут диалог с человеком (разумеется, не устный, а письменный) примерно в такой форме:
— Зачем же вы освобождали красный кубик?
— Чтобы поставить его на большой зеленый кубик,
— А зачем это было нужно?
— Чтобы поставить друг на друга красный кубик, большой красный брусок и большой зеленый кубик.
— А почему вы это сделали?
— Потому что вы меня об этом просили.
Как видите, на вопросы следуют вполне “человеческие” ответы...
Чтобы решать задачу такого рода, ЭВМ обязана вскрыть в фразе подлежащее, сказуемое и прочие грамматические формы, а затем выявить смысл. Всем этим более или менее успешно занимается сейчас математическая лингвистика, на языке формул описывающая человеческую речь. Но и тут работа идет со словами, тем или иным образом записанными. Как перейти к устному диалогу? Для этого придется спуститься еще на один “этаж”, туда, где решают проблемы опознавания и разделения звуков речи (сегментации). Не решив этих важнейших вопросов, нельзя шагать выше, к этажам грамматики, смысла, внутренней модели мира. Почему? Об этом дальше.
ИЗВЛЕЧЬ ИЗ РУЧЬЯ КАПЕЛЬКУ
Нашаречьнепрерывныйпотокзвуков...
Так мы говорим,— не отделяя слово от слова, а лишь делая логические паузы да приостанавливаясь, чтобы набрать воздуха. Речь журчит ручейком, это хорошо ощущал тот, кто учил, скажем, английский. Понятные на бумаге чужеязычные выражения становятся загадкой, когда их бегло произносит иностранец. Тут человек оказывается в положении “слышащей” вычислительной машины: он должен научиться узнавать чужие звуки, превращать их в “буквы”. В этом превращении вся сложность проблемы. Ведь каждой написанной букве соответствует звук речи — фонема, как говорят лингвисты. Но, поскольку промежутков нет, фонемы плавно переходят одна в другую, порождая споры между лингвистами и чиня массу препятствий специалистам, пытающимся построить ЭВМ, способную понимать речь.
В чем суть дела? В том, что букв столько, сколько их напечатано в алфавите, а вот сколько существует фонем — ученые не могут сосчитать, потому что не в состоянии прийти к единому мнению о фонемах вообще!
Вот три почти одинаковых слова: вода, воды, водонос. Первая гласная пишется одинаково, а звучит по-разному. В первом слове как “а”, во втором как “о”, а в третьем звук “съеден” и лингвисты обозначают его “ъ”.
Сторонник московской фонетической школы говорит, что это просто три разных варианта некой абстрактной фонемы “о”.
Приверженец ленинградской школы возражает: “Если это варианты, то как выглядит прототип? Разумно ли привязывать звуки к письменному изображению? Не лучше ли считать, что если в словах “вода” и “варежка” первая гласная слышится одинаково, то это одна и та же фонема?”
Но существует и третье мнение:
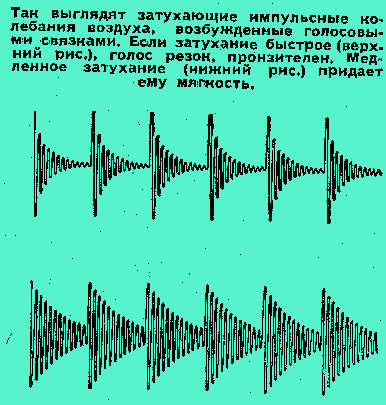
Так выглядят затухающие импульсные колебания воздуха, возбужденные голосовыми связками. Если затухание быстрое (верхний рисунок), голос резок, пронзителен. Медленное затухание (нижний рисунок) придает ему мягкость. “А по мне обе точки зрения стоят одна другой. Я занимаюсь машинным опознаванием речи. По логике москвичей получается, что три совершенно разных звука ЭВМ должна напечатать одной и той же буквой, а если правы ленинградцы, один и тот же звук нужно изображать двумя разными буквами. Где же однозначные правила, с которыми только и умеет оперировать машина?”
Некоторый свет проливают на проблему (хотя и не решают ее) дрессированные собаки. Они четко различают весьма обширный набор команд, который обязана выполнять, например, собака — проводник слепого: “Вперед”, “Тихо”, “Стоять”, “Вправо”, “Влево”, “Домой”, “Магазин”, “Работа”, “Парк” и так далее. Причем обучает инструктор, а выполняет собака команды владельца, у которого и тембр и другие особенности голоса совсем иные. Действия собаки сформированы на уровне условных рефлексов, она не понимает смысла слов, как понимает его человек, однако расшифровывает словесный сигнал совершенно правильно. Следовательно, для такой расшифровки нет нужды в использовании и столь высокой функции мозга, как мышление.
Что это так, подтверждают наблюдения над больными, у которых после мозгового расстройства пропадает способность к пониманию устной речи, но сохраняется понимание письменной. Если попросить такого больного повторять слова, которые он слышит в наушниках, он безошибочно сделает это, совершенно не осознавая их смысла. То есть слуховой и речевой тракты действуют, и лишь самый высший этап обработки информации поврежден.
В Лаборатории физиологии речи, которой руководит Л.А.Чистович, выдвинута гипотеза: для восприятия слов слуховой аппарат человека и животных обязан выделять некие признаки отдельных звуков, однако способность эта не имеет никакого отношения к речи как таковой. Умение выделять признаки существует просто потому, что оно жизненно важно для общения живых существ. Например, у ворон, как и у других птиц, есть сигнал “Опасность”. Однако крик американских ворон непонятен воронам французским. Зато птицы, которые бывают во время перелетов и в Америке и в Европе, способны всюду правильно реагировать на сигналы ворон-аборигенов. Коль скоро животные умеют распознавать звуки в силу специфики устройства своего слухового аппарата, то человек, без сомнения, унаследовал от них эту способность. А “изобретя” речь, он только воспользовался уже готовыми особенностями своего слухового аппарата. В частности, умением вскрывать границы между отличающимися друг от друга звуками.
Блестящая демонстрация справедливости такого вывода — опыты американских ученых над шиншиллами — грызунами, немного похожими на белку. Шиншилл научили различать слоги “
ta” и “da”. В английском эти слоги произносятся почти одинаково, оба начинаются с взрывного шума, потом—пауза, а на конце — одинаковый гласный звук. Разница же в том, что в “t” шум звучит дольше, чем в “d”. Если шум сокращать (а это лингвисты умеют делать с помощью электронных приборов, создающих звуки речи), то в какой-то момент “ta” превратится в “da”.И что же вы думаете? “Порог превращения” (то есть минимальная длительность шума, при которой еще, слышится “
ta”) совершенно одинаков что для шиншиллы, что для человека!Причина такого сходства кроется и в одинаковости устройства уха человека и других млекопитающих и в сходных методах обработки звуковой информации в более высоких отделах мозга.
Итак, признаки... Еще в начале 40-х годов профессор Ленинградского университета Л. Л. Мясников писал: “Если, например, звук “а” можно произносить на разные лады и все же отождествлять его при этом с “а”, то это означает, что его основа все время сохраняется”.
Впрочем, для понимания сути экспериментов ученого придется ненадолго отвлечься и поговорить не о слухе, а о речи.
КАК РОЖДАЕТСЯ СЛОВО
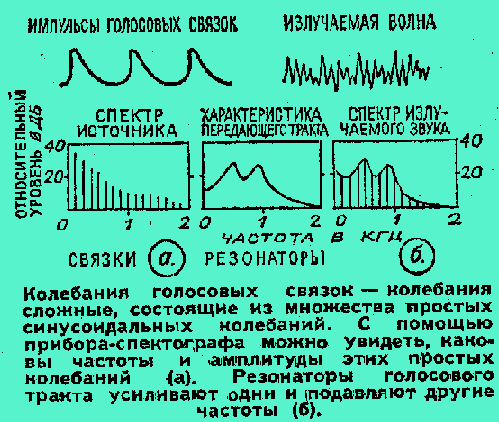
Голосовые связки поставляют речевому тракту “сырье” — импульсные колебания воздуха, в которых содержатся все мыслимые звонкие звуки любого языка мира, подобно тому, как в слитке металла заключена любая деталь автомобиля. Станок удаляет лишний металл и вскрывает форму детали. А звуки речи извлекаются из порожденных голосовыми связками колебаний с помощью резонаторов — полостей, образованных гортанью, ртом и носом.

Импульсные колебания, говорит теория,— это смесь колебаний самых различных частот. Мышцы языка и гортани, губ, шеи, нижней челюсти изменяют форму и объем резонаторов, иными словами, настраивают их на усиление той или иной частоты и подавление прочих. Это хорошо заметно на диаграммах, полученных с помощью прибора, который так и называется: “видимая речь”. Каждой фонеме — “букве” звуковой речи свойствен свой рисунок из подавленных и подчеркнутых главных частот — формант. (Пусть меня простят специалисты, но я не буду в дальнейшем пользоваться этим термином — “форманта”, чтобы не , усложнять изложение.) Общепризнано, что любую фонему можно создать, смешав в нужной пропорции четыре главные частоты. Вполне удовлетворительное звучание получается; если взять первую и вторую. На таком принципе и построены существующие синтезаторы речи. Правда, для управления хорошим синтезатором нужна вычислительная машина, которая умеет производить почти 100 тысяч операций в секунду.
Вернемся, однако, к распознаванию речи.
Можно ли решить задачу, обратную синтезу? По-видимому, да. Нет сомнений, что мы распознаем звуки по характеру главных частот, из которых фонема состоит. Главные частоты это и есть та “основа”, о которой писал профессор Мясников.
“ИСКУССТВЕННОЕ УХО”
РАЗРАБАТЫВАЕТСЯ В ОСАЖДЕННОМ ЛЕНИНГРАДЕ
В аппарате профессора Мясникова было восемь полосовых фильтров — четыре пары, соединенных особым образом наборов радиоэлементов. Фильтр похож на ворота в заборе: он пропускает только определенную группу (полосу) частот, а все остальные подавляет. Первый фильтр выделял колебания в полосе от 500 до 700 Гц, другой — от 800 до 1000 Гц, третий — от 4000 до 5000 Гц, четвертый... Впрочем, не будем вдаваться в подробности. Главное, что такое “искусственное ухо” различало некоторые фонемы с точностью до 75—80 процентов, даже если в микрофон говорили разные люди.
Ученый предполагал подключить к своему автоматическому анализатору фонем электрическую пишущую машинку, мечтал о создании автоматического “стенографа-диктографа” и даже такого телеграфного аппарата, которому можно было бы диктовать телеграммы по телефону. Он был убежден, что “полученные результаты подтверждают возможность подобных применений прибора”.
В своей статье о приборе Л. Л. Мясников не приводит ни одной обычной для научных публикаций ссылки на работы отечественных и зарубежных ученых. Не приводит потому, что аналогичных исследований просто не существовало. Выступление в “Журнале технической физики” было пионерным в полном смысле этого слова. В стандартной сухой сноске в конце статьи — слова: “Ленинград. Поступила в редакцию 10 ноября 1942 г.”. Уже четырнадцать месяцев воевал во вражеском окружении непокоренный город... Мрак, холод, голод
— и мечты о будущих электронных стенографах! Опыты, научное подвижничество, бескорыстное служение знанию...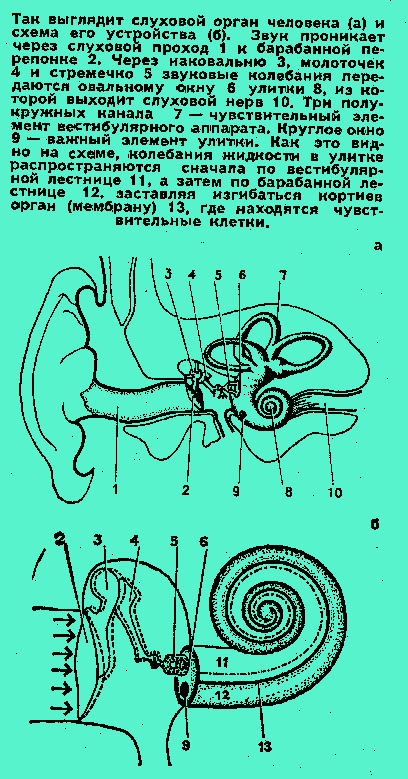
Идеи Мясникова на добрых десять лет опередили мысль зарубежных исследователей. В 1956 году фирма “Рэйдио Корпорейшн оф Америка” построила машину для распознавания речи, в принципе не отличающуюся схемой от схемы советского ученого. Там были и полосовые фильтры, и подключенные к ним измерители мощности сигналов, и логическое устройство, и пишущая машинка. Конечно, пролетевшие годы не минули даром: “распознаватель речи” уже мог воспринимать не только отдельные буквы, но и односложные слова. К 1970 году число слогов, с которыми справлялся автомат, возросло до тысячи! Сегодня 1979 год. И все-таки “слышащих машин” по-прежнему нет. Но не потому, что ложна идея, выдвинутая Л. Л. Мясниковым (нет, она верна!), а потому, что слишком уж непроста речь. Звуки-одиночки “электронное ухо” распознает вполне удовлетворительно, а едва от них переходят к естественной речи — автомат бастует: фонемы плавно переходят одна в другую, четкой границы между ними нет. И что уж совсем плохо — переходный участок, как правило, длиннее того, на котором звук более или менее стабилен. Это означает, что главные частоты все время “гуляют” по шкале частот и полосовые фильтры “путаются” при распознавании фонем.
ЛИНГВИСТЫ ПО-ПРЕЖНЕМУ СПОРЯТ
Чтобы выйти из тупика, выдвинута была такая идея. Чем искать, где на шкале времени находится фонема (не забывайте, что голос звучит непрерывно), не лучше ли заняться мгновенным распознаванием? Вырежем из непрерывного потока времени узенькую “ленточку”, скажем, в 1/100 секунды, и поглядим сквозь нее на речь. Уж тут-то, надо полагать, никаких изменений главных частот не случится: невелико время. И тогда удастся проанализировать набор главных частот и заключить, какую фонему он сейчас представляет.
Вот проведен один цикл анализа, второй, третий—прибор устойчиво показывает: “у”, “у”, “у”... А на четвертом цикле набор частот изменился, машина в недоумении. Ну и пусть! Это означает только, что фонема “у” кончилась и голос переходит на другую. Подождем, потерпим... На пятнадцатом цикле все опять пришло в норму, машина распознала фонему “а”. И так далее...
Соображения казались очень логичными; во многих лабораториях принялись строить подобные “слышащие машины”. Однако особых успехов и этот путь не принес.' Исследователи думали, что лингвисты, услышав звук в каждом таком отрезке (ясно, что его можно записать на пленку, склеить пленку в кольцо и слушать, сколько душе угодно), определят фонему и дадут тем самым ключевую информацию для ЭВМ. А оказалось, ничего такого лингвисты не могут. Чтобы определить фонему, человек нередко должен услышать все слово, в котором она звучит, .иной раз — даже группу слов. “Выбор признаков (фонемы.—В. Д.) оказывается вне пределов теории распознавания”— вот к какому неутешительному выводу пришли ученые.
Как ни странно, причина провала заключалась в том, что исследователи шли по пути, который всегда сулил удачи. “Самолет также мало похож на птицу, как торпеда на форель. Если бы человеку в самом деле вздумалось соорудить живую птицу, наверняка она у него не полетела бы... Для того чтобы осуществить то, что делает природа, он всегда вынужден был подходить к делу совершенно иначе.
В кортиевом органе улитки находятся чувствительные к звуку клетки. Если улитку развернуть, мы увидим, что каждая клетка максимально реагирует на “свою собственную” частоту, подобно струнам рояля.
I, II, III — первый, второй и третий витки улитки.В этом состоит невероятность и парадоксальность изобретений”,— писал Чапек.
Вот и в создании “искусственного уха” первые исследователи довольно мало обращали внимания на тонкости его строения, довольствовались самыми общими, самыми грубыми аналогиями. Профессор Мясников, как вы помните, обходился всего восемью чувствительными элементами, американские ученые — двенадцатью, а между тем в человеческом ухе около 25 тысяч чувствительных клеток, а количество, учит нас диалектика, неизбежно переходит в качество.
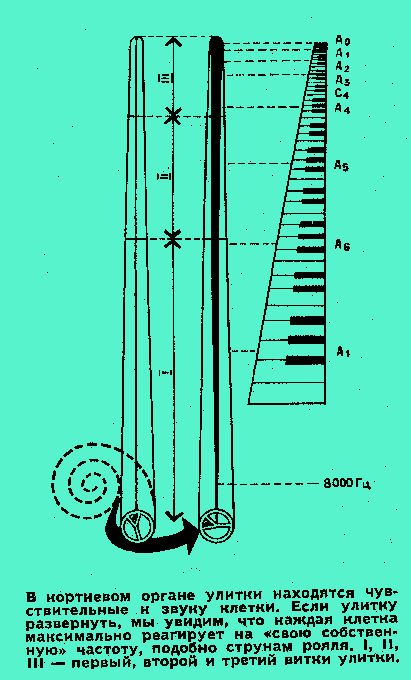
Второе отступление от живого прототипа состояло в том, что все конструкторы распознающих систем применяли фильтры с так называемой прямоугольной характеристикой. Это значит, что все частоты, которые фильтр пропускает, он пропускает равно “бесстрастно”, никакой не отдавая преимущества. А частотные характеристики живых фильтров—элементов уха выглядят совсем иначе: не прямоугольные ворота, а нечто, напоминающее холм с пологим длинным склоном, обращенным в область низких частот, и коротким, очень крутым, обращенным к частотам высоким. Крутизна этого склона колоссальна, примерно 200 децибел на октаву (отношение частот 2:1), иными словами, звук с частотой 2000 Гц, например, ослабляется таким фильтром в 10
000 000 000 раз по сравнению с 1000 Гц, на которую приходится вершина “холма”.Такая характеристика фильтра означает, что, ломимо основной частоты, на которую максимально реагирует клетка, она молчит при воздействии высоких частот, но отвечает (в меньшей степени) на низкие. Какой тут смысл? Выяснить этот вопрос удалось лишь в самое последнее время, когда в Лаборатории биофизики речи Института физиологии была построена под руководством В. А. Кожевникова электронная модель чувствительного аппарата уха — улитки. Она, эта модель, более тщательно, чем прежде, учитывает строение улитки естественной, и их характеристики поэтому близки.
Система фильтров с “холмообразными” характеристиками позволяет организовать очень удобную обработку информации, полученной с каждого фильтра по отдельности. Например, хорошо видно, какова по величине и как изменяется амплитуда сигнала, снимаемого с выхода данного фильтра (и в живом ухе клетки улитки обеспечивают тот же эффект). Значит, эту амплитуду можно измерить, сравнить с амплитудами сигналов, полученных с других выходов искусственной улитки, и выяснить, на каком из выходов она максимальна
—то есть отыскать, где на шкале частот находятся наши “главные частоты”. Иными словами, такая система фильтров дает возможность определять, какая произнесена фонема. Правда, вместо тысяч волокон слухового нерва из электронной модели выходят всего 128 проводов, но этот недостаток не вызывает тревоги: сокращение масштабов неизбежно при моделировании такого сложного явления, как живой организм.Между прочим, при работе с электронной улиткой обнаружился любопытный непредсказуемый эффект. Когда вместо звуков речи на ее вход подали белый шум (каждый, кто слышал водопад, представляет себе, что это такое), то на некоторых проводах, имитирующих нервы, ошеломленные исследователи обнаружили разные гласные звуки,— правда, произносимые как бы шепотом, но очень близкие к естественным. Устройство, призванное анализировать речь, оказалось своеобразным синтезатором!
В ПОИСКАХ НОВИЗНЫ
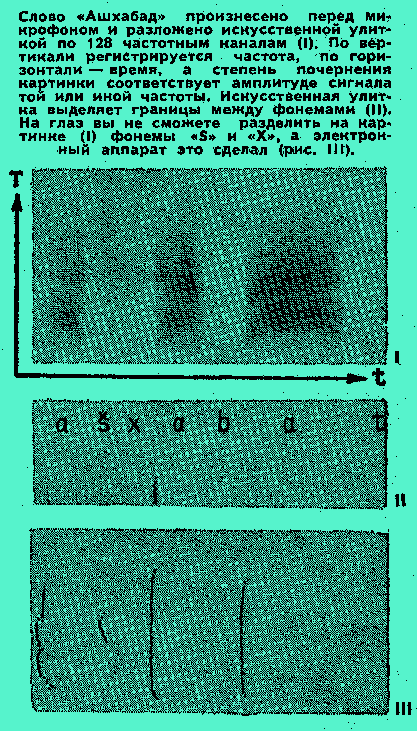
Море звуков... С тем большим удивлением выяснили ученые, что, например, у кошки более трети нейронов слуховой коры головного мозга “молчат”, когда животное слышит чистый тон. Оказалось, что некоторые из этих клеток реагируют только на щелчки и беспорядочные шумы, другие лишь отмечают увеличение или уменьшение частоты,— строгая специализация, явно для чего-то нужная. Для чего же? “Мы этого не знаем,—пишут авторы книги “Переработка информации у человека”.— Пользуются ли люди детекторами изменения частоты? Это также неизвестно. Возможно, что подобная информация
была бы полезна при анализе очень сложных звуковых комплексов, с которыми приходится иметь дело при восприятии речи”. И действительно, выяснили сотрудники института, детекторы изменений (не только частоты, но и других параметров звука) имеют к восприятию речи самое тесное отношение. Узнали это во время опыта, когда испытуемый слушал постоянную по громкости синтезированную фонему: ААААА — ААААА — ААААА... Внезапно в звуке появлялась маленькая “впадинке!” с крутыми краями: экспериментатор в каком-то месте чуть-чуть уменьшал амплитуду, и на экране контрольного прибора звук выглядел так: ААаАА — ААаАА — ААаАА. Испытуемый же утверждал, что слышит что-то среднее между ААМАА и ААНАА. После того, как у впадинки края из крутых превратились по воле экспериментатора в пологие, в наушниках послышалось не то ААЛАА, не то ААВАА. Небольшое изменение амплитуды гласного звука воспринимается как появление согласного. Постоянная амплитуда — сообщение тривиальное с точки зрения теории информации, а изменение огибающей (то есть воображаемой линии, соединяющей точки максимума амплитуды) — уже новизна, нетривиальность. Реагирующие на новизну нейроны и помогают слуховому аппарату обнаружить новый звук — иными словами, границу между фонемами. Ту самую границу, которая так упорно ускользала от исследователей! Значит, есть смысл создать электронный аналог, способный делать то же самое. Такая работа и была проведена в Лаборатории биофизики речи с помощью модели улитки.ЧТО СКАЗАЛА ЭЛЕКТРОННАЯ МОДЕЛЬ?

В нашем слуховом аппарате имеются, судя по всему, три системы, реагирующие на изменение огибающей (то есть амплитуды звука). Одна работает в полосе частот изменения огибающей 2—12 Гц, выделяя границы между слогами. Вторая занимает полосу 15—35 Гц и отмечает переходы между гласными и согласными в слоге. Третья же система (ее диапазон простирается от 40 до 250 Гц) вскрывает хриплость, то есть звуки типа “ж”, “з” и им подобные.
Эти результаты экспериментов с электронной моделью удивительно хорошо совладают со многими ранее полученными сведениями. Например, уже давно высказывались мнения о том, что главное в речи— не отдельные фонемы, а слоги. “Единственной реальной произносительной единицей является... слог”,— пишет Л. В. Бондарко в книге “Звуковой строй современного русского языка”. А чтобы отыскать границу между двумя слитно произносимыми слогами, чтобы разделить их и понять, слуховой аппарат использует частоты (изменения огибающей!), лежащие в
диапазоне 2—12 Гц.Ясно также, что внутри слога совершенно необходимо разделять гласный и согласный звуки. До сих пор это также не удавалось сделать, а электронная улитка впервые предоставила ученым такую возможность. Своей второй системой анализа звука (частота—15—35 Гц) она четко находит границы между гласными и взрывными согласными “п”, “б”, “т” и другими.
Но скептик, конечно, задаст вопрос: а где гарантия, что электронная модель действует точно так же, как и слуховой аппарат человека? Реальны ли найденные границы между слогами и звуками в слоге, или это только некие условные линии раздела?
Сотрудники института доказали, что модель очень близка к живому прототипу. Они изготовили на синтезаторе слог и дали его прослушать человеку и электронной улитке: пусть-ка определят, где проходит граница. Совпадение результатов было просто удивительным. Значит, открывается совершенно новый путь к конструированию “слышащих ЭВМ”: непременным их элементом будет отныне электронная модель нашего слухового аппарата, максимально копирующая характеристики живого органа. Сделан первый шаг на самых дальних подступах к созданию ЭВМ, способных понимать речь любого человека, а не только тех, на голос которых машина “надрессирована”.
Первый шаг. Но значение его громадно. Ведь это событие равносильно созданию, например, системы географических координат. Если до сих пор поиски признаков, важных для опознания звуков речи, формулировались на уровне “пойди туда — не знаю куда, принеси то — не знаю что”, то отныне первая часть формулы приобрела конкретность. Куда идти — известно. А значит, гораздо скорее пойдут и розыски того, что необходимо принести, то есть признаков, которые позволят ЭВМ узнавать фонемы, то
есть рано или поздно понимать человеческую речь.Слов нет, победные фанфары звучат куда торжественнее простого походного марша. Но без похода не бывает победы.
Научные популяризаторы по большей части пишут о результатах конечных, а черновая работа остается в тени. Между тем именно она-то и обеспечивает победу. Вот почему, не дожидаясь окончательного решения проблемных вопросов (а что такие успехи непременно будут —в этом сомнений нет!), я стал писать о буднях лабораторий, одних из тех, где ведется планомерная осада крепости, стоящей пока неприступно. И первая брешь, как мы видим, уже сделана. Более того, накоплен немалый материал, требующийся для построения многих блоков искусственного слухового аппарата. Так что тут уже дело не столько за физиологами, сколько, пожалуй, за конструкторами. Второй шаг — он уже близко.